
This is a form of data reduction for large datasets where one simply takes a random sample of the entire data. If the sample is sufficiently large, it should have similar statistical properties to the entire dataset.
Used in Chap. 13: page 162
Also used in hcistats2e: Chap. 11: page 125
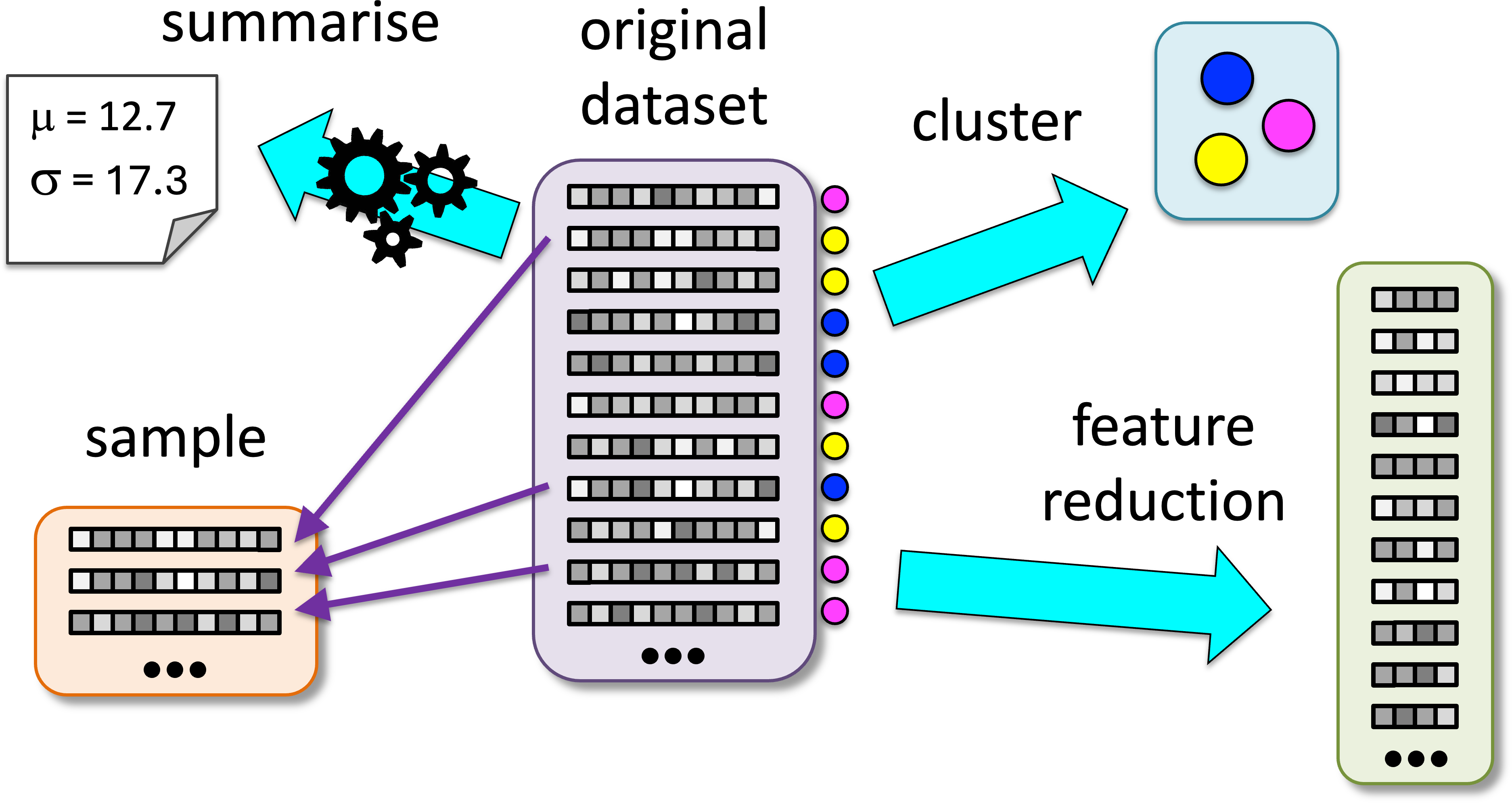
Data reduction methods. Fig 11.1 from Statistics for HCI (2e).